企业数据中台搭建
整合公司碎片化的数据系统
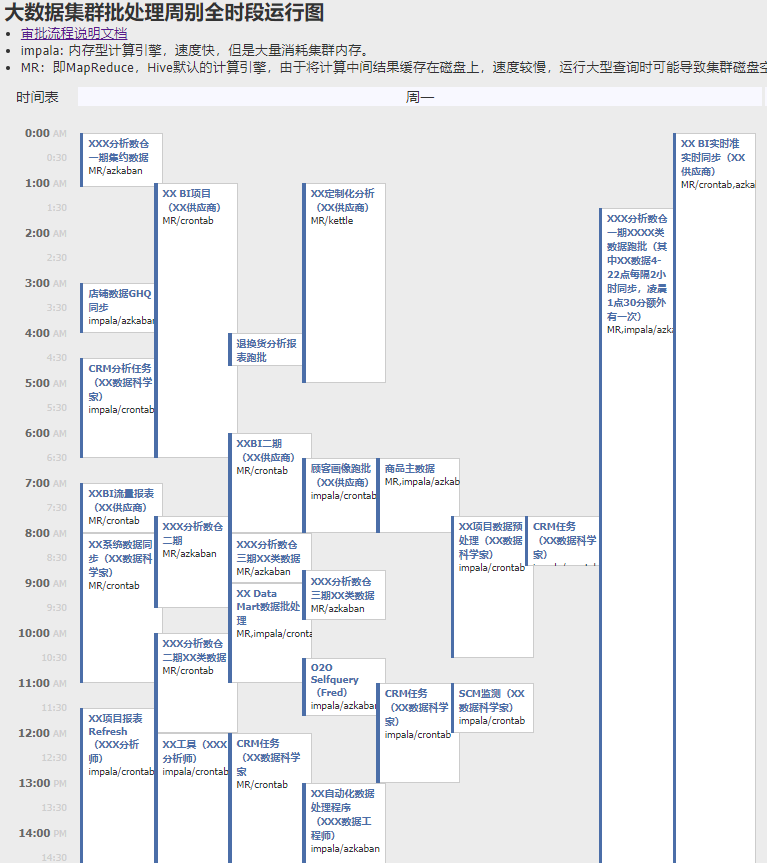
随着公司业务的复杂化,各领域的分析系统、BI系统层出不穷。由于历史原因,这些系统使用的技术架构、供应商和数据定义都各不相同,导致运维成本高昂,Metrics和KPI不统一。为了应对这个挑战,我作为架构师,在技术层面负责将所有BI系统整合并迁移到公司的大数据集群(Cloudera Hadoop)。在项目过程中,我负责的内容包括:
- 数据链路的规划、基于Kettle的PoC的开发。
- 数据批处理的压测。
- 脱敏机制的设计,脱敏的UDF的开发。
- 数仓分层设计、数据质量监控体系的开发。
统一供应商的技术规范
由于供应商过多,使用技术不统一,供应商对敏感数据、密钥文件的存放和权限管理不规范。为了解决这一问题,我基于自动化运维工具Ansible对集群的所有gateway节点进行统一初始化,利用DevOps来规范所有大数据ETL的开发和部署。
在节点上统一预装了包括大数据计算引擎(MR/impala/Spark)的驱动和运行环境,Azkaban,Kerberos的keytab文件等,对文件目录的权限进行了设置,并编写了开发部署的指导手册。
变革公司的报表系统
将数据驱动的理念推广到全国各家门店,同时避免商业报表系统的Licence成本,为了达成这个变革目标,我作为架构师,利用企业微信的Restful API、ECharts、Luckysheet和Web.py等技术,完成了一个PoC:将报表系统移植到企业微信中。利用企业微信全员使用的特点,近乎零成本地将报表系统向全店铺开。
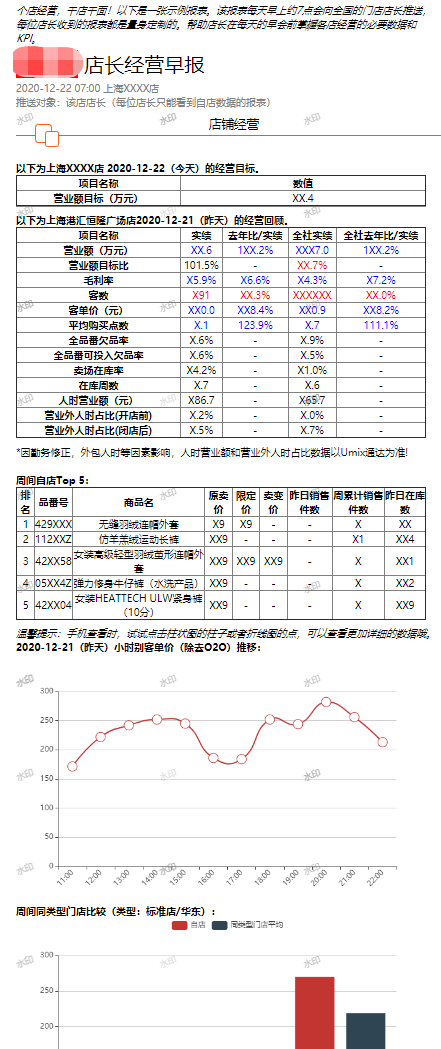
后来我又作为项目经理,利用企业微信的推送机制,与业务部门紧密合作,按照每个时间段店铺运营的特点,在需要的时间向需要的店铺员工推送需要的报表。(下图是其中一张报表的示意,数据并非真实!)
此外,我还主持开发了数据自助下载系统(SelfQuery),梳理公司总部的全部报表,根据日志分析报表的使用情况,淘汰一部分不必要的报表,将一部分“过度设计”的报表,替换成原始数据的自助下载链接。
完善本地数据和总部数据系统的对接机制
作为架构师,研究总部基于AWS的数据湖接口,并利用grpc、boto3等Python library开发了对接的程序,实现CN侧数据中台和GHQ数据湖的联通。
